 Stable Diffusion WebUI使用手冊
Stable Diffusion WebUI使用手冊  Stable Diffusion WebUI 从入门到卸载
Stable Diffusion WebUI 从入门到卸载 1.Stable Diffusion的工作原理
创建于 2024-02-04 / 最近更新于 2024-02-04 /
2835
这一方面看不懂可以直接跳过,不了解并不影响实际使用
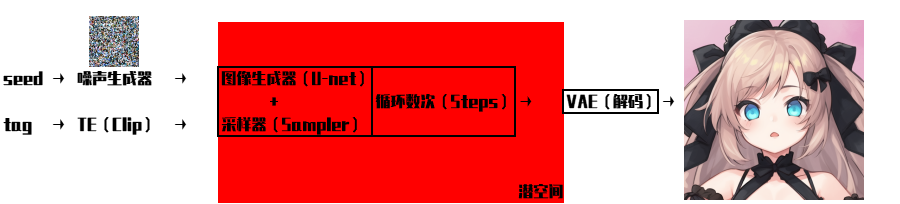
①首先我们输入的提示词(prompt)会首先进入TE(TextEncoder),而clip就是stable diffusion所使用的TE。TE这部分的作用就是把tag转化成U-net网络能理解的embedding形式,当然了,我们平时用的emb模型,就是一种自然语言很难表达的promot。(简单的说就是将“人话”转换成AI能够理解的语言)
②将“人话”转换成AI能够理解的语言之后,U-net会对随机种子生成的噪声图进行引导,来指导去噪的方向,找出需要改变的地方并给出改变的数据。我们之前所设置的steps数值就是去噪的次数,所选择的采样器、CFG等参数也是在这个阶段起作用的。(简单的说就是U-net死盯着乱码图片,看他像什么,并给出更改的建议,使得图像更加想这个东西)
③一张图片中包含的信息是非常多的,直接计算会消耗巨量的资源,所以从一开始上面的这些计算都是在一个比较小的潜空间进行的。而在潜空间的数据并不是人能够正常看到的图片。这个时候就需要VAE用来将潜空间“翻译”成人能够正常看到的图片的(简单的说就是把AI输出翻译成人能看到的图片)
经过以上三个步骤,就实现了“提示词→图片”的转化,也就是AI画出了我们想要的图片。这三个步骤也就对应了模型的三个组成部分:clip、unet、VA
5 人点赞过
本文档作者为:千秋九yuno779 https://civitai.com/user/Yuno779
转载申明:本站所有文档均为非商业性转载,便于用户检索和使用。版权归原作者所有。