 Stable Diffusion WebUI使用手冊
Stable Diffusion WebUI使用手冊  Stable Diffusion WebUI 从入门到卸载
Stable Diffusion WebUI 从入门到卸载 准备训练数据
创建于 2024-01-31 /
7994
1. 取得高品质图片
训练用的图片最少最少要准备10张。重质不重量。因为我要训练的是单一人物且风格固定,图片不宜有复杂背景以及其他无关人物。
网络图片一张一张右键下载当然可以,不过要大量下载图片的话我会使用Imgrd Grabber或Hydrus Network。
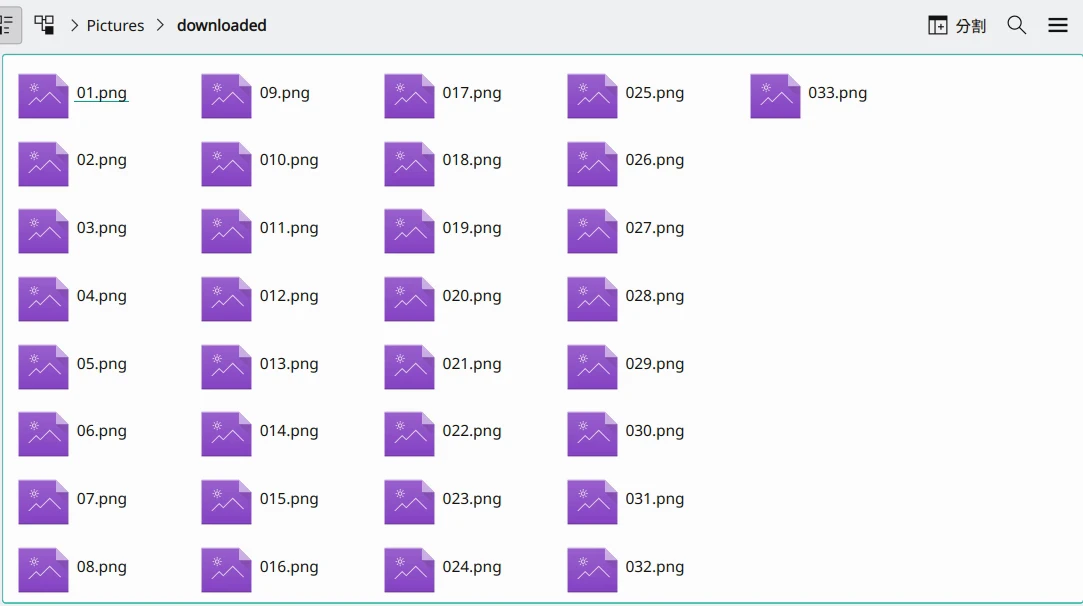
这里我准备了33张Hara绘制的斯卡萨哈
2. 裁切图片
下载图片后,要将训练图片裁切成512x512像素。你可以选择用SD WebUI自动裁切,或是手动裁切。
2.1. 自动裁切
裁切图片不会用到显卡计算。
- 将要裁切的图片放到同一个目录下,例如
/home/user/桌面/input。 - 打开SD WebUI,进到Train → Preprocess images页面
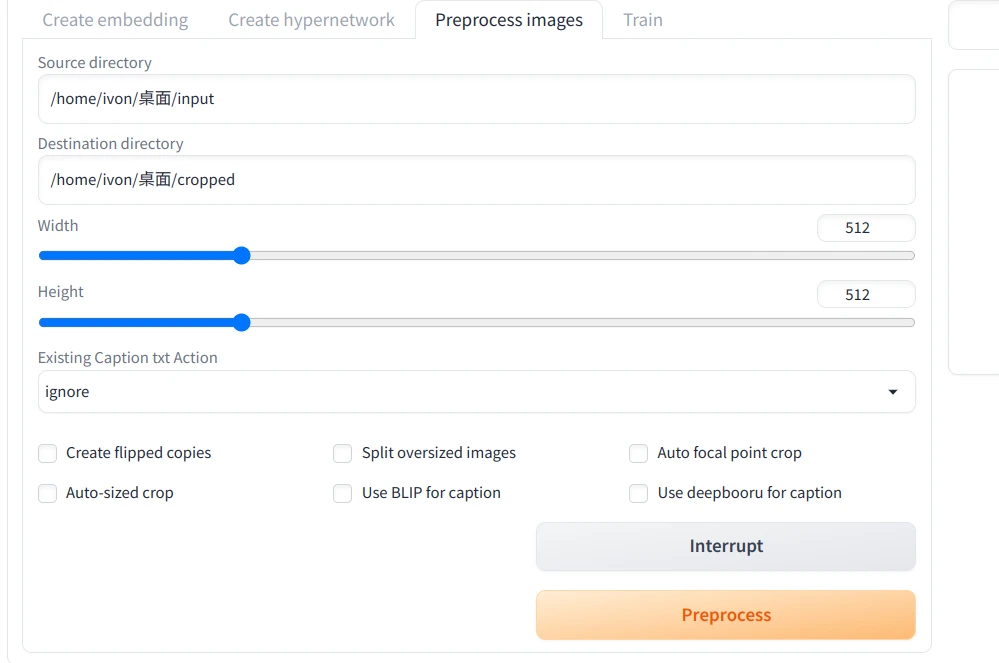
- 第一个字段
Source directory填写原始图片的路径 - 第二个字段
Destination directory填写输出路径,例如/home/user/桌面/cropped - Width和Height设置为512x512
- 点击Preprocess ,图片即会自动裁切。在那之后原始图片就可以删除,只留下裁切后的图片。
2.2. 手动裁切
手动把图片转成512x512理由是避免重要的部分被裁掉。
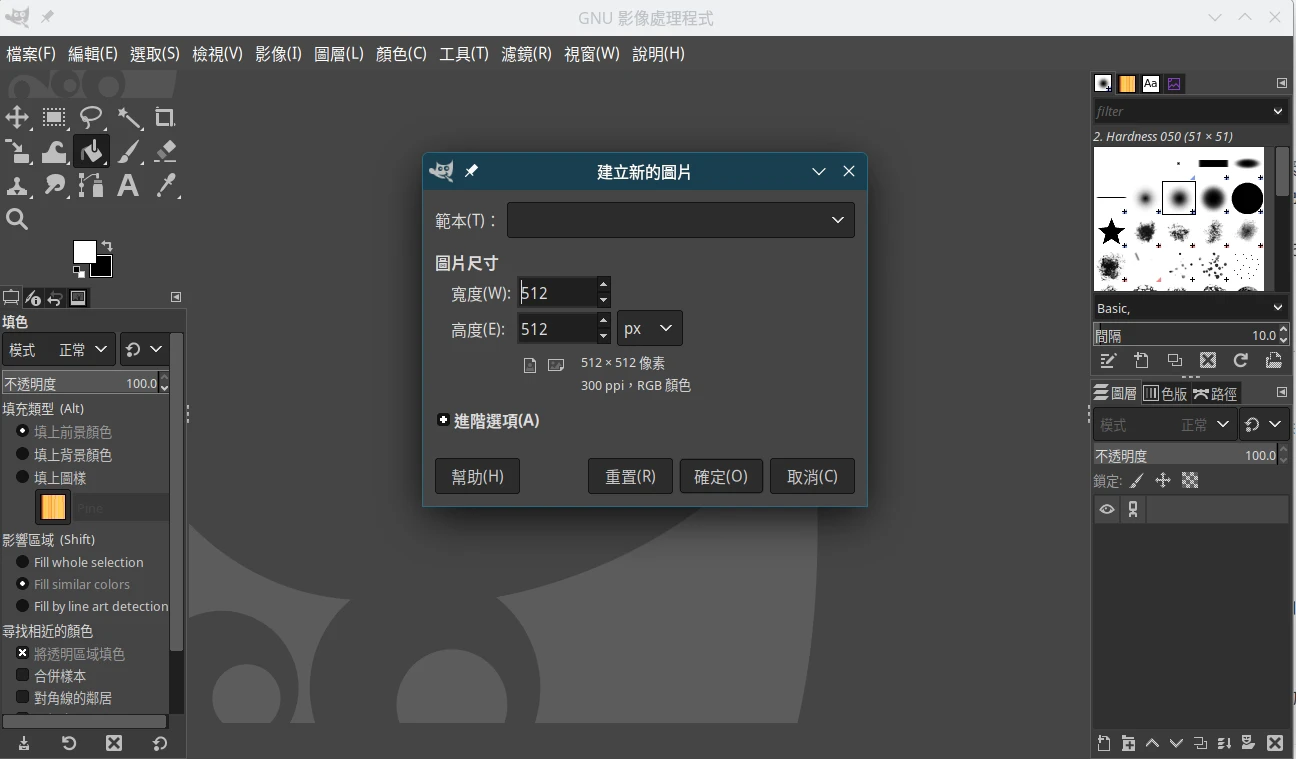
- 安装修图软件GIMP,点击文件→添加512x512像素的项目
- 点油漆桶将其漆成白色
- 将图片拖曳进画面,成为新的图层
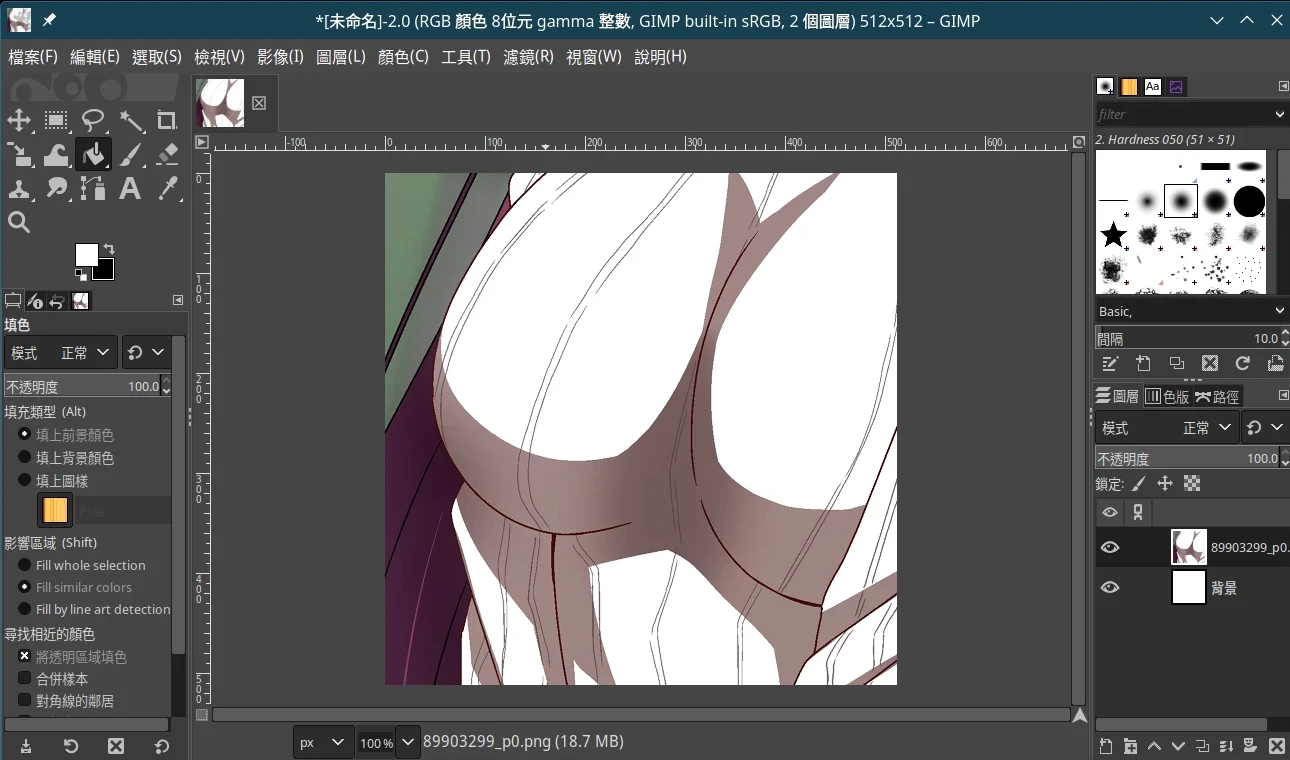
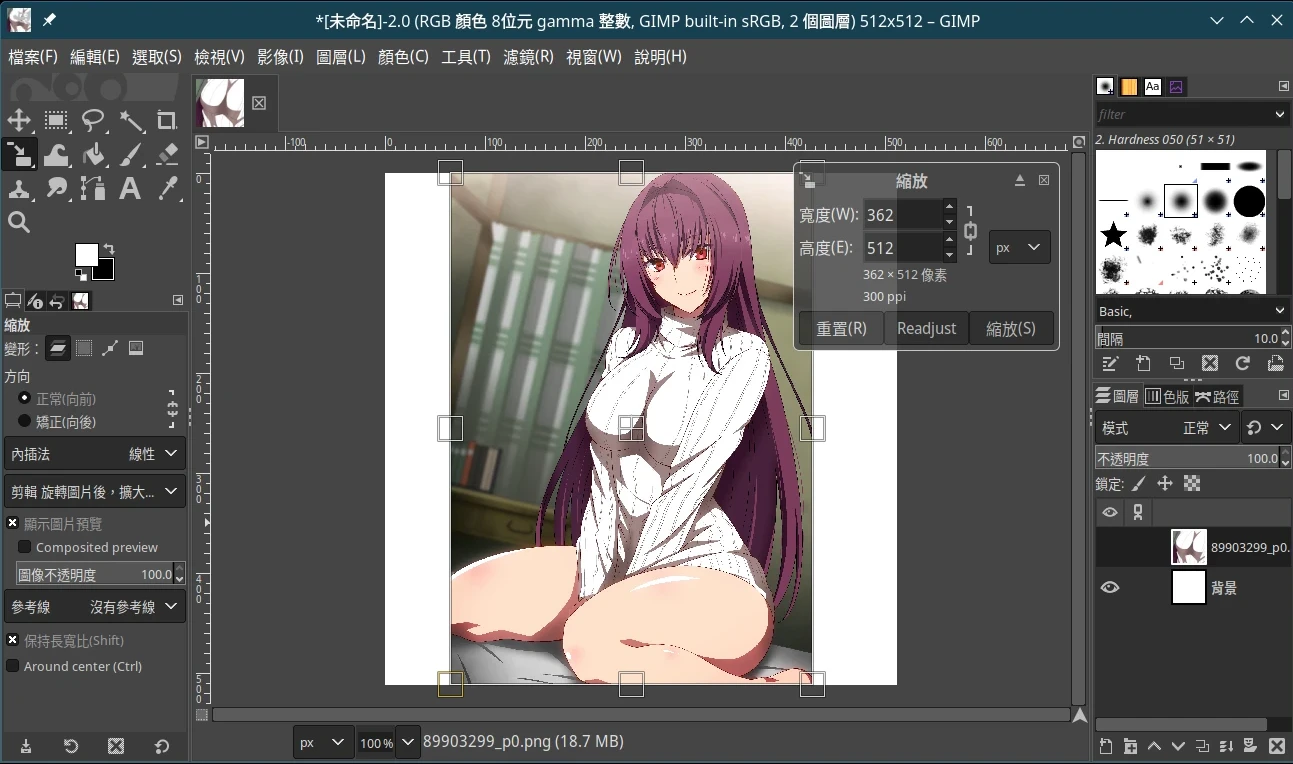
- 点击工具→变形工具→缩放,缩放图片使其符合目前画布大小,再按Enter。
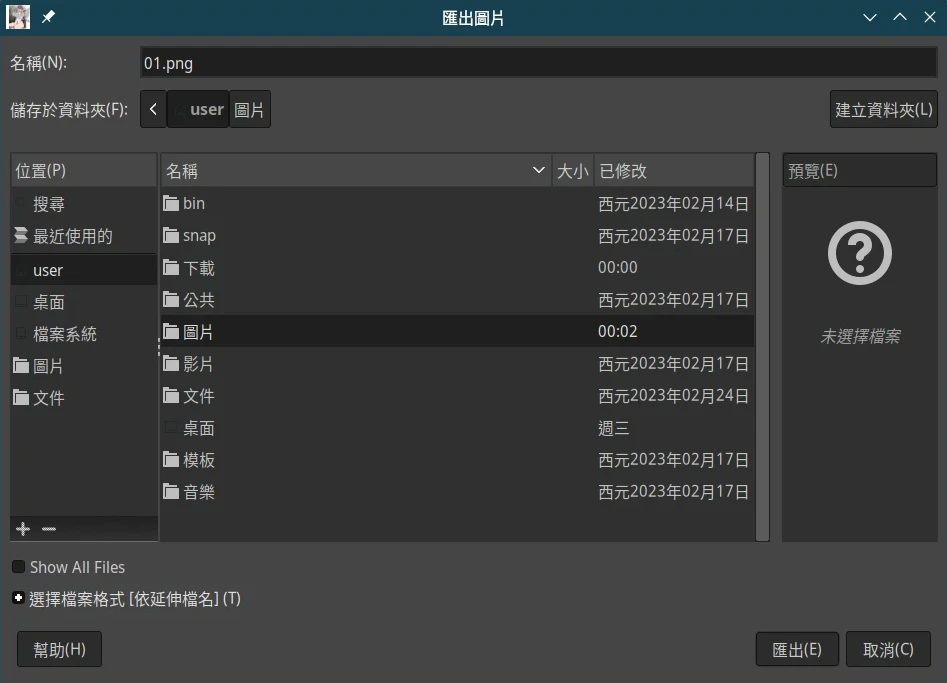
- 点击文件→Export,导出成png。
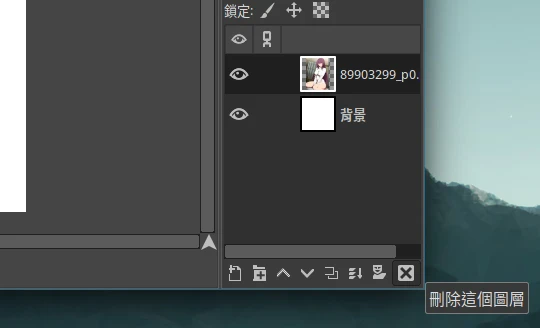
- 为加快后面图片的处理速度,按右下角删除目前图层,再拖新的图片进来,重复操作。
- 将33张Hara绘制的斯卡萨哈裁切后,统一放到名为
raw的目录。
3. 预先给图片上提示词
接着要给图片预先上提示词,这样AI才知道要学习哪些提示词。
- 启动SD WebUI,进入Train页面。
- 进入Preprocess页面,
Source输入裁切图片的路径,Destination填处理后图片输出的路径。
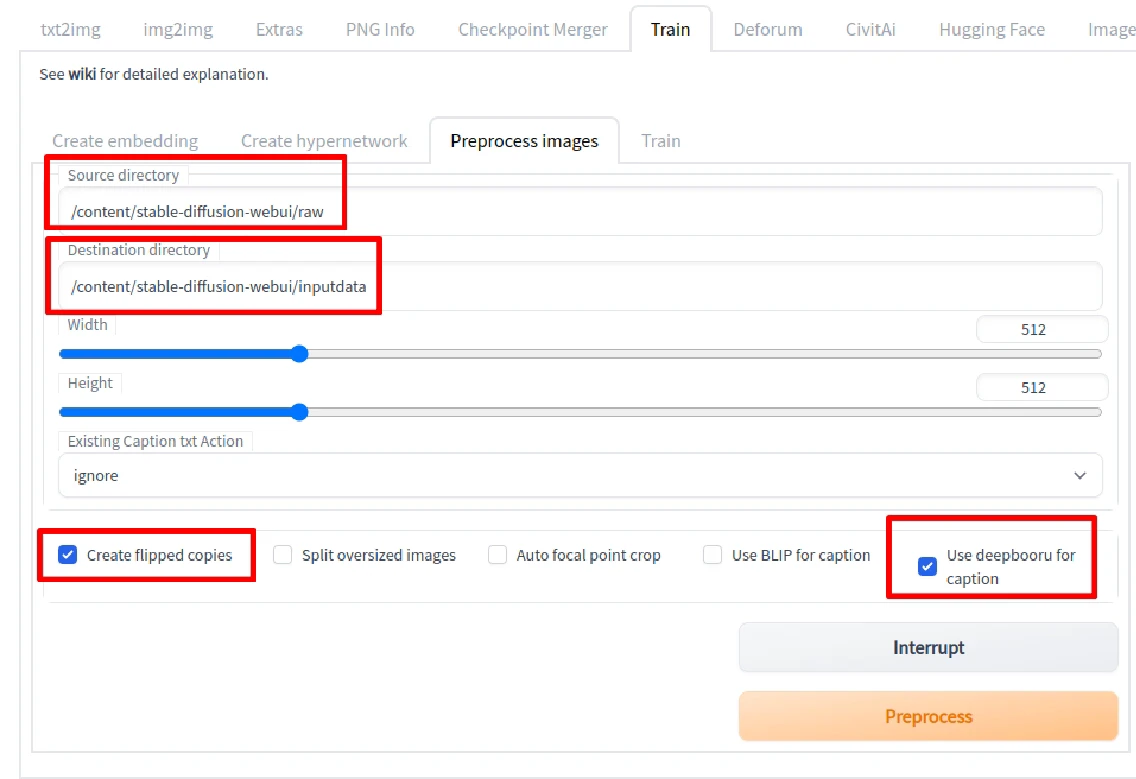
- 接着勾选
Create Flipped Copies,创建翻转图片提升训练数量。
然后用Stable Diffusion训练真实图片的勾选Use BLIP for caption;训练动漫人物改勾选Use DeepBooru for caption。
- 点击Preprocess,约几分钟后便会处理完成。输出的目录里面会含有每张图片对应的提示词txt档。
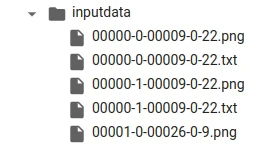
- 点击打开txt档,将你觉得无关的特征都删除,例如
2girls这类太笼统的提示词。 - 至此训练数据准备完成。
9 人点赞过
此手册的中文贡献者: Ivon Huang
转载申明:本站所有文档均为非商业性转载,便于用户检索和使用。版权归原作者所有。